Multimodal reasoning often relies on two intermediate representations: language models reason through text, while vision-language systems reason over static images. Many questions, however, are inherently dynamic: how an object moves, how a structure changes, how a physical process unfolds, or how a geometric relation evolves over time. Thinking with Video asks a direct question: what if a video generation model could make the reasoning process visible as a sequence of frames?
Video as a reasoning medium
The generated video is not only an output. It becomes a visible trajectory that represents the model's dynamic reasoning process.
Unified multimodal representation
Text conditions, visual states, and temporal evolution are grounded in one video trajectory instead of separate text and image channels.
VideoThinkBench
The benchmark covers visual puzzles, dynamic understanding, mathematics, and multidisciplinary question answering.
Composable reasoning strategies
Self-consistency and in-context learning further improve performance, suggesting that video reasoning can be strengthened systematically.
Why Reason with Video
A static image captures only a moment, while text often compresses spatial, temporal, and motion relations into discrete symbols. For visual puzzles, physical processes, action prediction, and geometric transformations, this compression can remove essential information. Video generation models can simulate what follows from a condition, turning a hypothetical process into an inspectable trajectory.
This does not claim that the model has a complete internal world model. The point is that video provides a medium closer to dynamic reality: a model can generate candidate processes and use frame-level changes to support a final answer.
The Paradigm
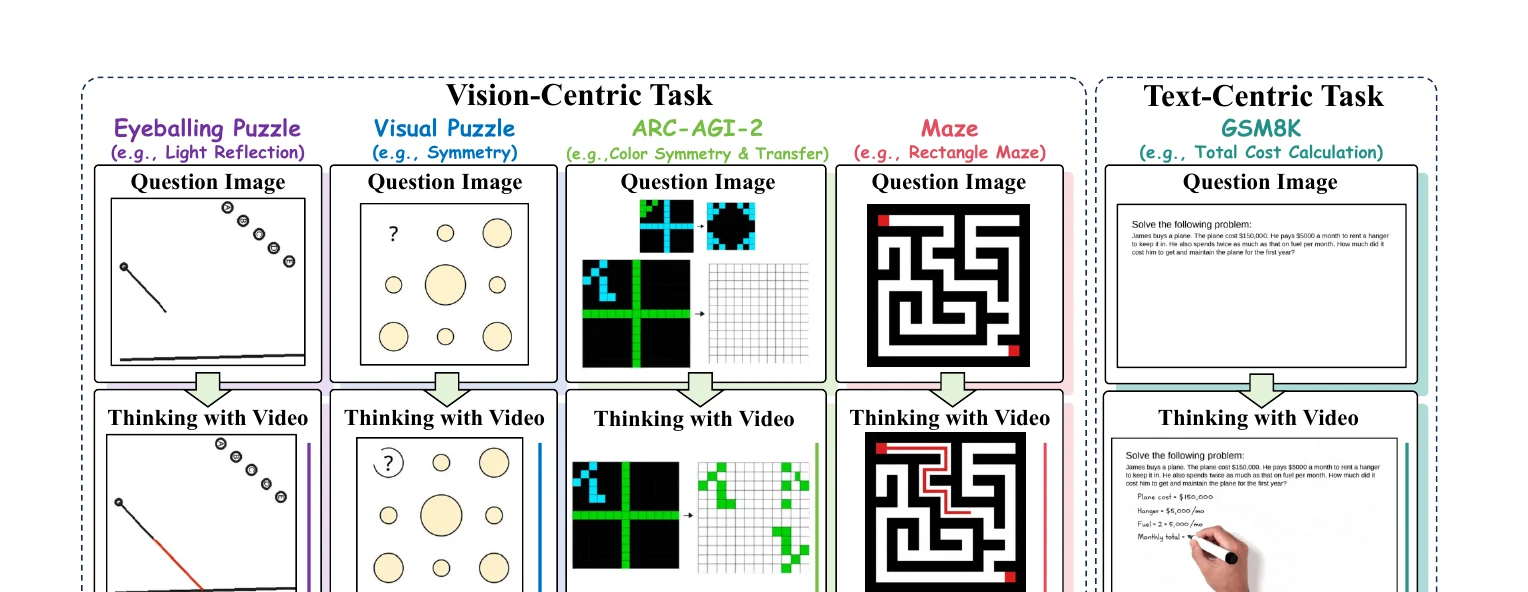
In Thinking with Video, the model receives a question, image, or text condition, then generates a video as an intermediate reasoning artifact. On vision-centric tasks, the video can reveal object relations, occlusion changes, and geometric evolution. On text-centric tasks, it can act as a multimodal scratchpad that maps abstract problems into visualized steps.
The workflow changes the role of a video generation model from "what should be generated" to "what process supports the answer." Multiple generations enable self-consistency, and examples can guide the model toward more stable video reasoning patterns.
VideoThinkBench
To evaluate this capability, the paper introduces VideoThinkBench. It includes vision-centric tasks such as Eyeballing Puzzles and text-centric tasks such as GSM8K, MATH, and MMMU. This design avoids evaluating video models only by visual quality and instead asks whether generated processes help answer reasoning questions.
The results show that video generation models such as Sora-2 are already competitive with strong vision-language models on vision-centric tasks. The paper reports that Sora-2 surpasses GPT-5 by about 10% on Eyeballing Puzzles, while also reaching 92% on MATH and 69.2% on MMMU.
What It Changes
The contribution is not that every reasoning problem should become a video problem. Instead, it identifies a new direction: a generative model can use its strongest modality as the reasoning space. Text chain-of-thought is well suited for symbolic steps, images for static structure, and video for time, motion, and causal processes.
Video reasoning still faces high generation cost, error accumulation, verifiability, and hallucination. But it gives researchers a concrete way to turn the dynamic modeling ability of video generators into measurable and improvable reasoning behavior.