Top scientists do more than read papers, write code, and run experiments. They judge which problems are worth pursuing and which directions may have lasting impact. AI Can Learn Scientific Taste defines scientific taste as the ability to judge and propose high-impact research ideas, then formulates it as a preference modeling and alignment problem.
RLCF
Reinforcement Learning from Community Feedback learns preferences from large-scale scientific community signals instead of costly expert labels.
Scientific Judge
Given the titles and abstracts of two papers, the model reasons about which work is likely to have higher impact.
Scientific Thinker
Given a paper, the model proposes follow-up research ideas and is aligned with the Judge as a reward model.
Generalizable taste
The Judge generalizes to future years, unseen fields, and peer-review preferences; the Thinker transfers to later research topics.
Scientific Taste Is Not Arbitrary Preference
The paper treats scientific taste not as an individual's subjective whim, but as a collective judgment formed through long-term community interaction. If a work is repeatedly reused, extended, and cited, it reflects a durable community preference about research value. Citations, reuse, and review preferences can therefore provide learning signals for scientific judgment.
This perspective addresses a missing component in AI scientist systems. Current models can retrieve literature, write code, and execute experiments, but without a sense of which direction is worth pursuing, they struggle to close the expert research loop.
RLCF: Reinforcement Learning from Community Feedback
RLCF starts from a practical observation: scientific ideation has no single ground-truth answer, making RLVR difficult to apply directly. RLHF is also limited because expert annotation is expensive and cannot easily capture long-term community-scale preference. The team instead constructs preference pairs using community feedback such as citations, matching papers by field and publication time.
The workflow has three steps. First, collect papers and community feedback. Second, train Scientific Judge to decide which of two papers has higher impact. Third, use the Judge as a generative reward model to train Scientific Thinker to propose stronger follow-up ideas.
Scientific Judge Learns Research Judgment
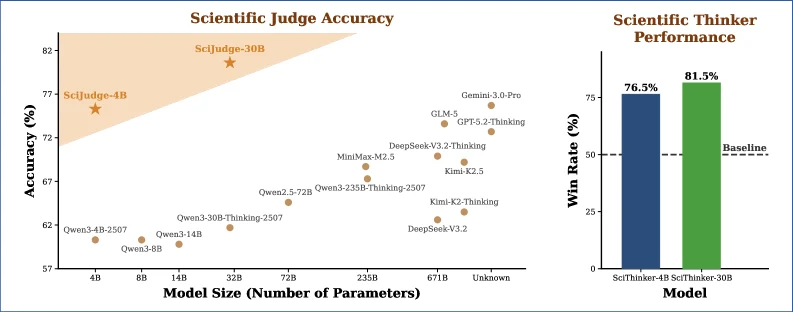
SciJudgeBench contains 700K arXiv paper pairs. Each pair is tightly matched by field and publication year while showing a significant citation difference. This design discourages shortcuts based only on year, domain, or topic popularity, pushing the model to learn deeper signals from titles and abstracts.
Experiments show that Scientific Judge improves with both data scale and model scale. A Judge trained from Qwen3-30B outperforms frontier closed models such as GPT-5.2 and Gemini 3 Pro, while also generalizing to 2025 papers, unseen disciplines, and ICLR review-score preferences.
Scientific Thinker Uses Judgment to Improve Creativity
If Judge is the research critic, Thinker is the research idea generator. Given a paper, it proposes a potentially high-impact follow-up idea. During training, the Judge compares generated ideas pairwise within a group; the within-group win rate becomes the reward, a process the paper calls comparison-based GRPO.
After training on high-citation papers from January to July 2025 using only about 4K examples, Scientific Thinker reaches a 70-80% win rate over its base model and generalizes to later research topics. Better judgment can therefore guide stronger scientific creativity.
Toward Expert-Level AI Scientists
This work decomposes "scientific taste" into two trainable abilities: judgment and ideation. Judge identifies which research is more likely to matter; Thinker proposes directions with higher potential. Together, they form a loop from evaluation to generation.
Citations are not the whole of scientific value, and the model does not yet possess full human scientific judgment. But RLCF provides a scalable starting point: learn value signals from long-term community feedback, then use those signals to generate better research ideas.