Video generation has advanced rapidly in visual quality, duration, and motion consistency, yet many systems still treat audio as a post-processing step: first generate a silent video, then add speech, sound effects, or music with a separate model. This cascaded design often produces lip-sync errors, delayed effects, and a weak sense of acoustic space. MOVA starts from a different premise: video and audio should be generated together.
Native video-audio generation
Supports text-to-video-audio and image-to-video-audio, producing synchronized visuals and sound directly.
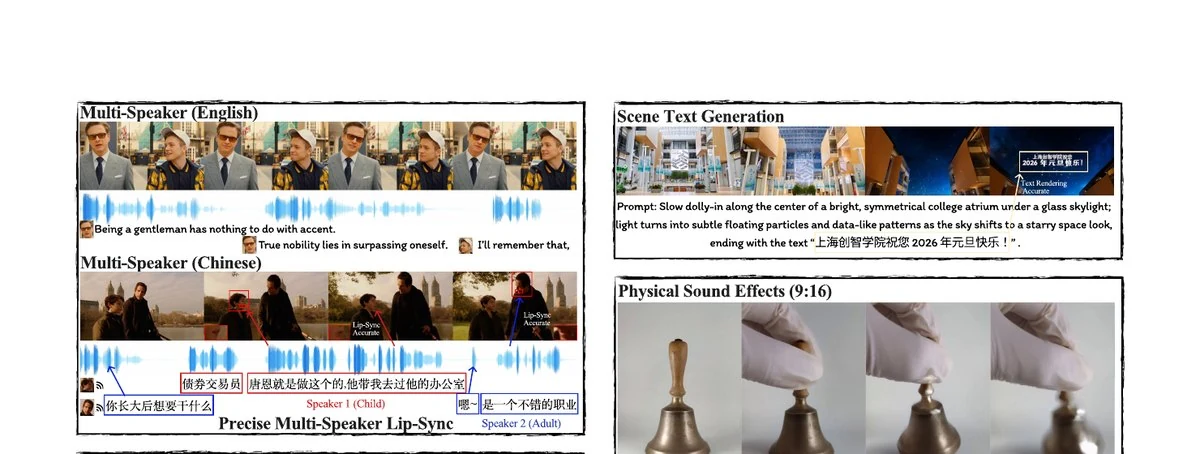
Lip-synced speech
Handles Chinese and English dialogue, speeches, and multi-person conversations with aligned mouth motion and intonation.
Contextual sound effects
Generates sounds for vehicles, wind, gunshots, footsteps, and room reverberation in sync with visual actions.
Full-stack open source
Releases model weights, training code, inference code, and fine-tuning recipes for research and applications.
Why Native Video-Audio Models Matter
Conventional video generation optimizes visual realism first, while audio is often added by an independent system. But sound is part of the physical event. A vehicle turning in sand, a person speaking, or a street scene with gunfire all require audio, motion, semantics, and spatial cues to cohere. MOVA treats this as a joint generation problem.
Heterogeneous Dual Towers and Bidirectional Bridge
MOVA uses an asymmetric dual-tower architecture coupling a large video backbone with a smaller audio backbone. The video tower builds on the 14B-parameter Wan 2.2 I2V model, while the audio tower comes from a 1.3B-parameter text-to-audio diffusion model. A bidirectional Bridge lets hidden states cross between the towers at each layer, so video can react to audio rhythm and audio can follow visual motion and spatial structure.
Audio and video have very different temporal densities. Video is frame-based, while audio is much denser. MOVA introduces Aligned ROPE to map audio and video tokens onto the same physical timeline, reducing drift at the representation level.
Multi-stage Data Pipeline
MOVA's data pipeline preserves as much original video-audio information as possible while controlling quality, synchronization, and annotation granularity. Raw data is first cut into fixed-length clips; then filtered by audio quality, video quality, and audiovisual synchrony; finally, audio understanding models, visual understanding models, and LLM fusion produce fine-grained video-audio descriptions.
This lets the model learn not only what appears in the frame, but also why a sound occurs, when it occurs, and which visual action it belongs to.
From 360p Alignment to 720p Refinement
MOVA uses a three-stage training strategy. Stage 1 learns basic audio-visual and lip-motion alignment at 360p. Stage 2 stabilizes synchronization and semantic details at the same resolution. Stage 3 moves to 720p, focusing computation on high-resolution visual detail without breaking the learned synchronization structure.
MOVA also introduces Dual Sigma Shift and dual CFG. The former assigns different noise shifts to audio and video, reducing implicit modality dependency. The latter separates text guidance from Bridge guidance, allowing users to trade off visual fidelity, instruction following, and lip-sync precision. LUFS loudness normalization keeps audio stable under strong guidance.
Agent Workflow
A strong base model still benefits from better user-intent interpretation. MOVA's deployment workflow first parses the initial image with a vision model, then rewrites the prompt with a general LLM using both the visual constraints and user instruction, and finally performs dual-conditioned generation from the first frame and rewritten prompt. This workflow improves consistency when user prompts are raw, underspecified, or slightly mismatched with the first frame.
Evaluation and Open-source Value
MOVA is evaluated on audio quality, audiovisual alignment, lip-sync accuracy, and speech accuracy, and is also tested with an Arena-style human preference evaluation. The key lesson is that video-audio generation should not be judged only by whether the image looks good. Sound, motion, semantics, and space must work together.
By open-sourcing the full stack, MOVA gives developers a direct model for content creation and gives researchers a concrete system for studying dual-tower diffusion, bridge-based fusion, temporal alignment, training strategies, and inference-time control.