When speech must not only read the text correctly, but also sound like a particular speaker, stay stable across long narration, switch smoothly between Chinese and English, and satisfy explicit duration constraints, conventional sentence-level TTS systems reach their limits. MOSS-TTS is positioned as a speech-generation foundation model: it unifies voice identity, prosody, pronunciation, duration, and long-context stability in a scalable generation framework.
Zero-shot voice cloning
Reconstructs voice timbre, speaking rate, pause patterns, and expressive style from short reference speech.
Long-form generation
Targets documentaries, audiobooks, and long explanations, reducing manual segmentation and stitching.
Duration and pronunciation control
Allows fine-grained intervention over speech rate, length, pinyin, phonemes, and local pronunciation.
Multilingual speech
Supports major languages and smooth language switching, including Chinese-English mixed speech.
From TTS Model to Speech Foundation Model
MOSS-TTS does not treat speech synthesis as plain text-to-audio conversion. Real speech carries speaker identity, semantic content, emotional density, stress, pauses, speaking rate, and cross-lingual pronunciation habits. A speech foundation model therefore needs three ingredients: a high-fidelity audio representation, large and diverse real-world training data, and an architecture that can model long discrete sequences reliably.
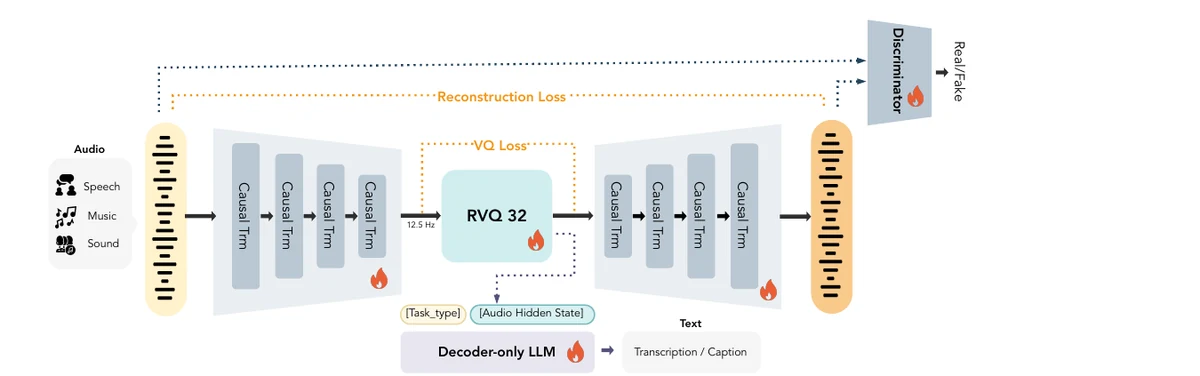
MOSS Audio Tokenizer
The interface underneath MOSS-TTS is MOSS Audio Tokenizer, built on Cat, a Causal Audio Tokenizer with Transformer. It turns continuous audio into discrete tokens for autoregressive modeling. With a pure causal Transformer design and multi-layer RVQ mechanism, it preserves high-fidelity reconstruction at low bitrates while retaining speech semantics.
Instead of relying on existing pretrained audio models such as Whisper or HuBERT, the tokenizer learns directly from raw audio. This gives speech, sound effects, and music a shared discretization interface, which later supports MOSS-TTS, dialogue speech generation, sound-effect generation, and real-time systems.
Data Engine and Multi-track Assets
Speech quality comes from data engineering as much as model design. MOSS Data Engine converts massive raw audio into reusable training assets across long narration, dialogue, character voice design, and sound-effect generation. The pipeline governs audio quality, content alignment, trainability, and task structure through multi-stage filtering and consistency checks.
For MOSS-TTS, long-form stability, multilingual generalization, zero-shot cloning, and pronunciation control are not isolated features. They share the same representation and data standards, which is why MOSS-TTS can serve as the foundation for the broader model family.
Two Architectures
To cover both deployment and research needs, MOSS-TTS trains and releases two complementary architectures. The Delay-Pattern architecture uses a single Transformer backbone with multiple heads for RVQ codebooks, and delay scheduling to stabilize multi-codebook token generation. It is suited for long-form narration, content generation, and large-scale deployment.
The Global Latent + Local Transformer architecture lets the backbone emit a global latent at each step, then uses a lightweight local Transformer to generate token blocks. This route is lighter, more direct, and more streaming-friendly, making it a strong baseline for low-latency interactive systems.
Editable Speech Generation
Production workflows often require control over how something is pronounced, how long the utterance should be, where pauses appear, and how local expression changes. MOSS-TTS supports pinyin and phoneme-level controls, allowing users to adjust polyphonic characters, tones, and local pronunciation while preserving naturalness.
Role in the MOSS-TTS Family
MOSS-TTS is the foundation model behind the MOSS-TTS Family. MOSS-TTSD targets multi-speaker dialogue, MOSS-VoiceGenerator targets character voice design, MOSS-SoundEffect targets environmental audio, and MOSS-TTS-Realtime targets streaming interaction. Together they form a sound-production stack for creation workflows and product systems.
Open Source and Ecosystem
The MOSS-TTS route emphasizes scalability, reproducibility, and deployability. For the research community, the dual-architecture design and unified audio tokenizer provide strong baselines for comparison and ablation. For engineering teams, MOSS-TTS offers a path from high-quality offline synthesis to real-time system integration.