多模态推理通常依赖两类中间表示:语言模型用文本链式思考,视觉模型用静态图像理解场景。 但很多问题本质上是动态的:物体如何移动、结构如何变化、力学过程如何展开、几何关系如何在时间中显现。 Thinking with Video 提出一个直接的想法:让视频生成模型把推理过程显式展开成视频,再从生成的帧序列中完成判断。
视频作为推理媒介
不再把视频只看作输出结果,而是把连续帧当作模型的可视化思考轨迹,用来表达动态过程。
统一多模态表示
将文字条件、视觉状态和时间演化压到同一条视频轨迹中,减少文本推理与视觉生成之间的割裂。
VideoThinkBench
构建覆盖视觉谜题、动态理解、数学和多学科问答的评测,用来观察视频生成模型的推理边界。
可组合推理策略
自一致性采样和上下文示例能进一步提升表现,说明视频生成也能承载类似推理增强机制。
为什么需要“用视频思考”
静态图像只能捕捉一个瞬间,文本又经常需要把空间、时间和运动关系压缩成离散符号。 对视觉谜题、物理过程、动作预测和几何变换来说,这种压缩会丢掉关键线索。 视频生成模型具备从条件出发模拟后续画面的能力,因此它天然可以把“如果这样,会发生什么”变成一段可观察的轨迹。
这并不意味着模型真的在内部拥有完备的世界模型。 关键在于,视频为推理提供了一种更贴近动态世界的外显媒介:模型可以生成多个候选过程,再根据帧序列中的状态变化选择答案。
范式:生成一段可被读取的过程
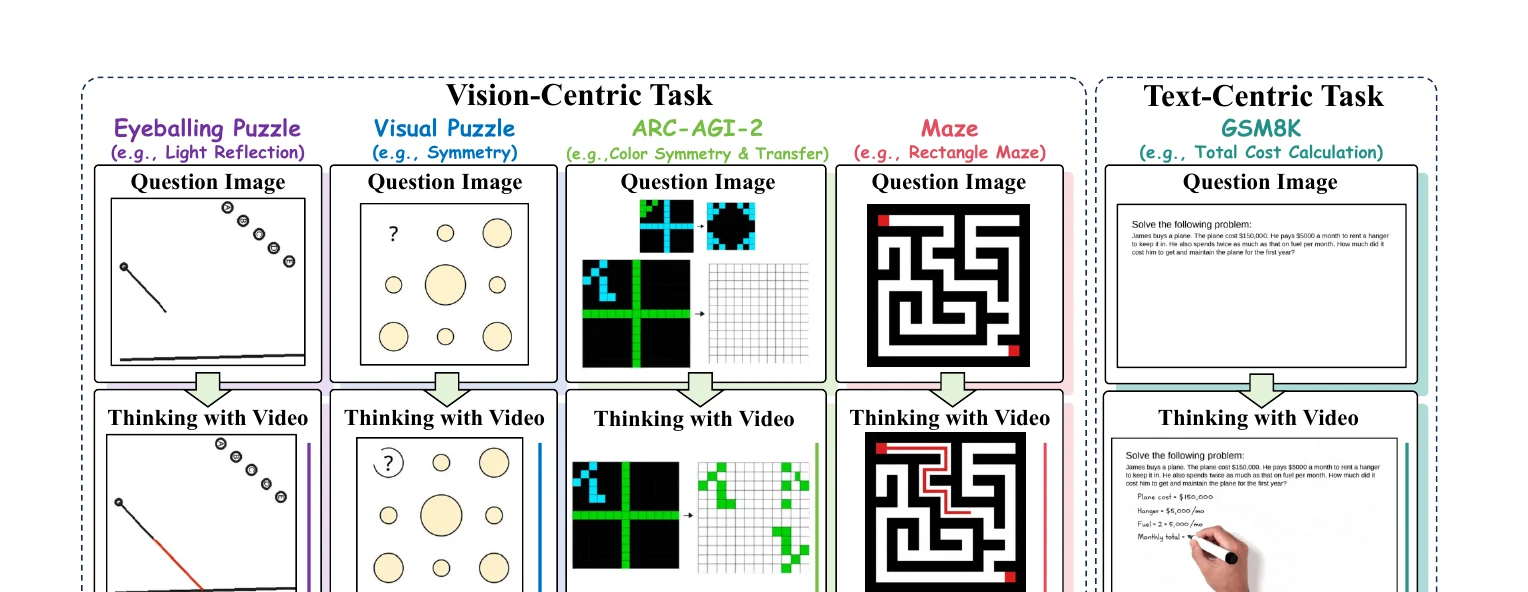
在 Thinking with Video 中,模型接收问题、图像或文字条件,然后生成一段视频作为中间推理结果。 对于视觉中心任务,生成的视频可以展示物体关系、遮挡变化或几何结构如何演化;对于文本中心任务,视频也可以作为一种多模态草稿,把抽象问题落到可视化步骤中。
这种流程使视频生成模型不仅回答“生成什么”,也回答“为什么会这样”。 当任务需要多个候选路径时,可以通过多次生成进行自一致性比较;当任务需要示例诱导时,也可以通过上下文样例引导模型形成更稳定的视频推理模式。
VideoThinkBench:从视觉谜题到学科问答
为了系统评估这种能力,论文提出了 VideoThinkBench。 评测既包含视觉中心任务,如 Eyeballing Puzzles,也包含文本中心任务,如 GSM8K、MATH 和 MMMU。 这样的设置可以避免只看“画面是否逼真”,而是直接追问:生成过程是否真的帮助模型做出正确判断。
结果显示,在视觉中心任务上,Sora-2 等视频生成模型已经能与强视觉语言模型竞争;在 Eyeballing Puzzles 上,论文报告其超过 GPT-5 约 10%。 在文本中心任务上,视频生成模型也并非只能处理视觉题:论文报告 Sora-2 在 MATH 上达到 92%,在 MMMU 上达到 69.2%。
它改变了什么
这项工作的重点不是把所有推理都改写成视频,而是指出一个新的方向:生成模型可以用自身擅长的模态作为推理空间。 文本链式思考适合符号演算,图像适合静态结构,视频则适合时间、运动和因果过程。 当模型能在这些媒介之间切换时,多模态推理就不再只是“看图答题”,而是开始接近“模拟过程后再判断”。
当然,视频推理还面临生成成本、错误累积、可验证性和幻觉等问题。 但它提供了一个清晰的研究入口:把视频生成模型的动态建模能力转化为可评测、可组合、可改进的推理能力。