顶尖科学家不仅会阅读文献、写代码和跑实验,更重要的是能判断什么问题值得做,什么方向可能产生长期影响。 AI Can Learn Scientific Taste 将这种“科研品味”定义为判断和构思高影响力研究想法的能力,并把它转化成一个偏好建模与对齐问题。
RLCF
提出 Reinforcement Learning from Community Feedback,从大规模科研社区反馈中学习偏好,而不是依赖昂贵人工标注。
Scientific Judge
输入两篇论文的标题和摘要,推理判断哪一篇具有更高影响力,学习科研判断力。
Scientific Thinker
给定一篇论文,提出后续研究想法,并由 Judge 作为奖励模型持续对齐。
可泛化的品味
Judge 在未来年份、未见领域和同行评审偏好上都能泛化,Thinker 也能迁移到更晚出现的研究主题。
科研品味不是主观任性
论文中的“科研品味”不是个人偏好,而是社区长期互动后形成的集体判断。 一项研究如果被持续复用、扩展和引用,说明它契合了学术共同体对价值的长期选择。 因此,引用、复用和评审偏好等社区反馈可以成为训练 AI 科研判断力的信号。
这个视角补上了 AI 科学家系统中的关键短板。 现有模型可以检索文献、生成代码和执行实验,但如果缺少“什么方向值得投入”的判断,就很难形成专家级研究闭环。
RLCF:从社区反馈中强化学习
RLCF 的核心洞察是:科研构思没有唯一标准答案,传统 RLVR 很难直接使用;RLHF 又受限于专家标注成本,并且难以覆盖社区尺度的长期偏好。 团队因此用引用等社区反馈构建偏好信号,在相同领域、相近发表时间的论文之间形成高低影响力对比。
整个流程分为三步:第一,收集论文及社区反馈;第二,训练 Scientific Judge,让模型判断两篇论文哪一篇更有影响力;第三,用 Judge 作为生成式奖励模型,训练 Scientific Thinker 提出更有潜力的后续研究想法。
Scientific Judge:学会科研判断力
SciJudgeBench 包含 70 万对 arXiv 论文,每一对论文在领域和发表时间上严格匹配,并具有显著引用差异。 这种设计避免模型只学到年份、领域或热门主题的浅层偏差,而是逼迫它从标题和摘要中识别更深层的研究价值信号。
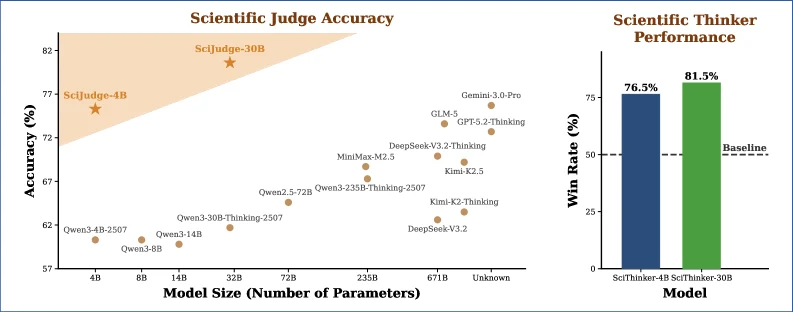
实验显示,Scientific Judge 随数据规模和模型规模提升而持续变强。 基于 Qwen3-30B 训练的 Judge 超过 GPT-5.2、Gemini 3 Pro 等前沿闭源模型,并且在 2025 年未来论文、未见学科领域以及 ICLR 评审偏好等测试上保持泛化能力。
Scientific Thinker:用判断力训练创造力
如果 Judge 是科研鉴赏家,Thinker 就是科研构思者。 它的任务是给定一篇论文,提出一个可能更有影响力的后续研究想法。 训练时,Judge 对同一组候选想法进行两两比较,组内胜率被用作奖励,这一过程被称为基于比较的 GRPO。
在 2025 年 1 月到 7 月的高引论文上训练、仅使用约 4K 数据后,Scientific Thinker 产生的想法相对基座模型达到 70-80% 胜率,并能泛化到晚于训练数据的研究主题。 这说明更好的科研判断力可以反过来引导更强的科研创造力。
迈向专家级 AI 科学家
这项工作把“科研品味”从难以描述的专家直觉拆解为两个可训练能力:判断力与构思力。 Judge 负责识别什么样的研究更可能产生影响,Thinker 负责提出更有潜力的新方向。 二者合在一起,形成了 AI 科学家从评估到生成的闭环。
这并不意味着引用数就是科研价值的全部,也不意味着模型已经拥有完整的人类科学判断。 但 RLCF 给出了一个可扩展起点:用社区长期反馈训练 AI 识别价值,再把这种识别能力用于生成更好的研究想法。