过去一年,视频生成模型在画面质量、时长和运动一致性上快速进步,但许多系统仍然把声音视为后处理步骤:先生成无声视频,再由另一个模型配音或补音效。 这种级联系统容易出现口型不准、音效滞后、空间感割裂等问题。 MOVA 的目标是从一开始就把视频与音频放在同一个生成过程中,让画面、语音、音效和音乐共同建模。
端到端音视频生成
支持文本到音视频、图像到音视频,直接生成同步画面和声音,而不是后期拼接。
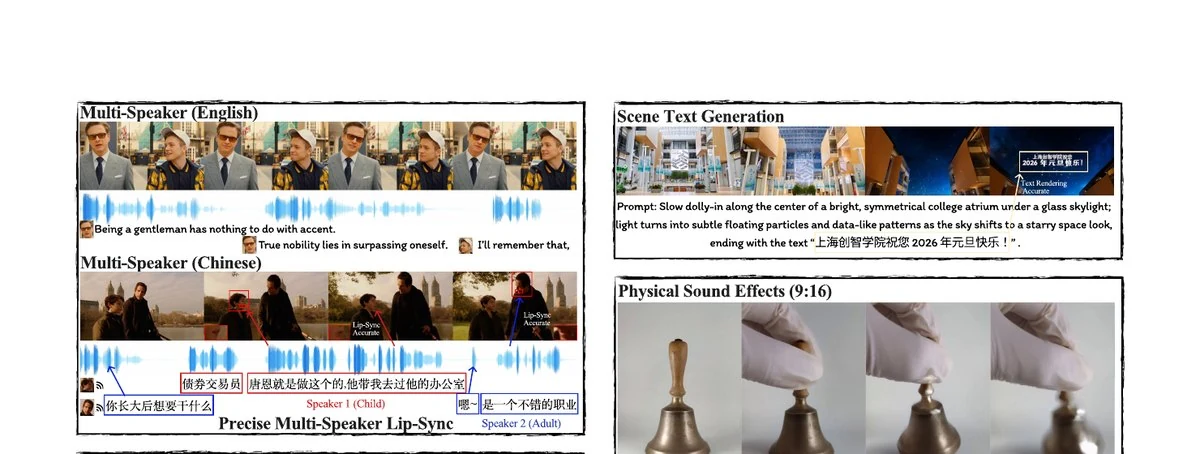
口型同步语音
面向中英文对话、演讲和多人谈话,保持口型、语义、表情和语调之间的一致性。
环境音效契合
为车辆、风声、枪声、脚步和空间混响等动态场景生成与画面动作同步的声音反馈。
全栈开源
开放模型权重、训练代码、推理代码和微调方案,降低音视频基模研究与应用门槛。
为什么需要原生音视频模型
传统视频生成优先追求画面拟真,声音常常由独立模型补齐。但真实世界中的声音不是附属物,而是物理过程的一部分。 车轮卷起沙尘时会伴随马达与路面声,人物开口时唇形、表情和语调应该同时变化,空间中的枪声、回声和装备摩擦也应与画面结构一致。 MOVA 把这些要素作为联合生成问题处理。
异构双塔与双向 Bridge
MOVA 采用非对称双塔架构,将大尺寸视频生成骨干与小尺寸音频生成骨干耦合起来。 视频塔基于 14B 参数的 Wan 2.2 I2V,音频塔来自 1.3B 参数的文本到音频扩散模型。 两个塔之间通过双向 Bridge 交换隐藏状态,使视频在生成过程中感知声音节奏,音频也能捕捉画面动作和空间结构。
音频和视频的时间密度天然不同。视频通常以帧为单位,音频信号则更密集。 为避免生成过程中出现时间轴漂移,MOVA 引入 Aligned ROPE,把音频 token 与视频 token 映射到同一物理时间尺度上,从底层降低不同步问题。
多阶段数据管线
MOVA 的数据处理不是简单裁剪视频,而是尽量保留原始音视频信息,并对质量、同步性和描述粒度进行分阶段治理。 第一阶段将原始数据预处理为固定长度、固定帧率和分辨率的视频片段;第二阶段根据音频质量、视频质量和音视频同步性筛选高质量片段;第三阶段分别进行音频理解、视觉理解和大语言模型融合,生成细粒度音视频描述。
这种管线让模型不只学习“画面里有什么”,还学习“声音为什么出现、何时出现、与哪个动作相关”。 对端到端音视频生成而言,这种跨模态标注比单模态 caption 更关键。
从 360p 对齐到 720p 精修
MOVA 采用三阶段训练策略。第一阶段在 360p 上建立音频与口型、动作之间的基本对齐;第二阶段仍在 360p 上稳定同步质量并细化语义;第三阶段提升到 720p,把算力集中到高清画面和更细致的空间建模上。 这种由粗到细的策略降低了随机初始化 Bridge 的训练难度,也避免过早追求高画质而破坏同步结构。
在训练与推理中,MOVA 还引入 Dual Sigma Shift 与双重 CFG。 前者为音频和视频设置不同的噪声偏移,减少隐式模态依赖;后者把文本引导和模态桥接引导分开调节,让用户可以在画质、指令遵循与口型同步之间做明确取舍。 为避免强引导带来的音量畸变,系统还使用 LUFS 响度归一化稳定输出音频。
Agent 工作流
高性能基模并不等于用户输入总是足够清晰。MOVA 在实际部署中加入三阶段 Agent 工作流:先用视觉模型解析首帧图像,再用通用语言模型结合视觉约束重写提示词,最后由 MOVA 同时接受首帧和重写后的提示词进行双重条件生成。 这让系统能更好处理原始、含混或与首帧略有偏差的用户需求。
评测与开源意义
在 Verse-Bench 等评测中,MOVA 重点验证了音频质量、音视频对齐、口型同步和语音准确度等指标。 团队还引入 Arena 人类偏好评测,让用户在不同模型生成结果之间投票,以补充客观指标难以覆盖的整体观感。 这些评测共同指向同一件事:音视频生成的关键不只是画面是否漂亮,而是声音、动作、语义和空间是否共同成立。
MOVA 的全栈开源补上了端到端音视频基础模型的重要一块。开发者可以直接使用模型生成内容,也可以研究双塔 Diffusion、Bridge、时间对齐、训练策略与推理控制如何共同工作,并在垂直场景中继续微调。