当一段语音不仅要读对文本,还要像某个说话者自然地表达、在长篇内容中保持稳定、在中英文之间平滑切换,并满足明确的时长约束时,传统单句 TTS 系统就会暴露出边界。 MOSS-TTS 的定位是语音生成基座模型:它把音色、韵律、发音、时长和长上下文稳定性统一到一个可扩展的生成框架中,为内容生产、交互系统和语音模型研究提供基础能力。
零样本音色克隆
从少量参考语音中复现说话者的音色、语速、停顿方式和表达风格,不只是套用一个声线。
长语音生成
面向纪录片、有声内容和长篇讲解等场景,减少人工分段、拼接和后处理带来的工程负担。
时长与发音控制
支持对语速、生成长度、拼音和音素级发音进行细粒度干预,在自然度和可控性之间取得平衡。
多语言与混说
覆盖中文、英语、法语、德语、西班牙语、日语、俄语、韩语、意大利语等语言,并支持语言切换。
从 TTS 模型到语音生成基座
MOSS-TTS 不把语音生成视为简单的“文本转音频”任务。真实语音包含说话人身份、内容语义、情绪强度、局部重音、停顿、语速和跨语言发音习惯等多个层次。 因此,基座模型需要同时解决三类问题:音频表示是否足够高保真,训练数据是否覆盖真实场景,生成架构是否能稳定建模长序列。
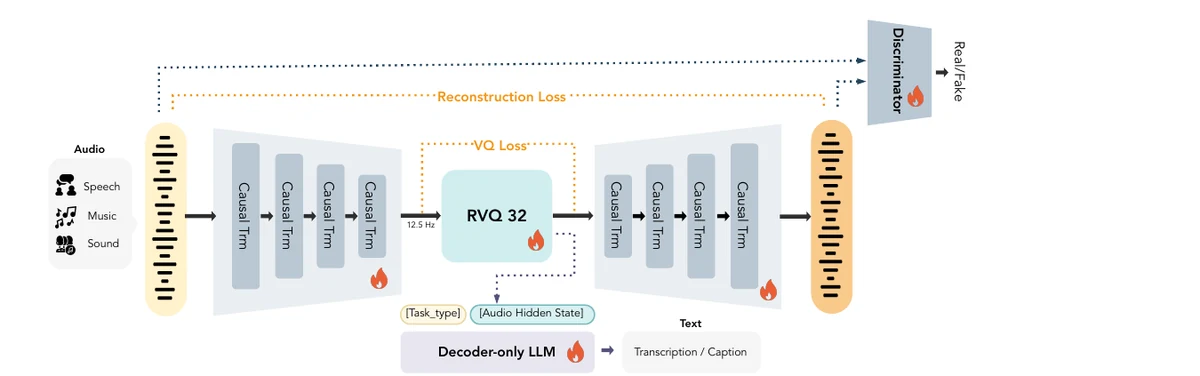
MOSS Audio Tokenizer
MOSS-TTS 的底层接口是 MOSS Audio Tokenizer。它基于 Cat 架构,即 Causal Audio Tokenizer with Transformer,将连续音频转为适合自回归建模的离散 token。 该 tokenizer 采用纯 Transformer 因果结构和多层 RVQ 机制,可以在低码率下保持高保真重建,同时保留与文本语义相关的声音信息。
与依赖 Whisper、HuBERT 等既有音频预训练模型的路线不同,MOSS Audio Tokenizer 直接从原始音频中学习统一表征。 这种设计让语音、音效和音乐等音频形态可以进入同一套离散化接口,也为后续的语音基座模型、对话语音模型和音效生成模型提供了统一底座。
数据引擎与多轨训练资产
语音生成能力很大程度上来自数据工程。MOSS Data Engine 将海量原始音频转化为可训练资产,覆盖长时叙事、对话交互、角色塑造和环境音效等任务形态。 这套流程不是简单清洗数据,而是围绕音频质量、内容对齐、可训练性和任务类型进行多阶段治理,并通过交叉一致性验证提高训练信号的可靠性。
对 MOSS-TTS 而言,长语音稳定性、多语言泛化、零样本音色复刻和发音控制并不是彼此孤立的功能,而是共享同一底层表示与数据标准的多种生成能力。 这也是 MOSS-TTS 能够作为 Family 中多个成员基础能力的原因。
双架构并行:覆盖性能与时延取舍
为兼顾工程落地与研究复现,MOSS-TTS 同时训练并开源两套互补架构。 第一类是 Delay-Pattern 架构,通过单一 Transformer 主干和多输出头建模 RVQ 多码本 token,并用 delay scheduling 稳定处理多码本之间的时序关系。 它更适合长篇叙述、内容生成和规模化部署。
第二类是 Global Latent + Local Transformer 架构。主干网络在每个时间步输出全局潜变量,再由轻量局部 Transformer 发射 token block。 这一设计更轻、更直接,也更适合流式输入输出和实时交互场景。 两条路径共同构成了从离线高质量合成到在线低时延合成的技术谱系。
细粒度控制:让语音生成可编辑
在真实生产中,用户常常需要控制“读成什么音”“读多久”“哪里停顿”“局部语气如何变化”。 MOSS-TTS 支持拼音和音素级控制,使创作者可以直接调整多音字、声调和局部发音,甚至使用纯拼音输入驱动生成。 这种能力把 TTS 从一次性生成工具推进到可编辑、可实验、可组合的声音生产环节。
在 MOSS-TTS Family 中的位置
MOSS-TTS 是整个 MOSS-TTS Family 的基座。围绕这一基座,MOSS-TTSD 面向多说话人对话生成,MOSS-VoiceGenerator 面向角色声音设计,MOSS-SoundEffect 面向环境音和音效生成,MOSS-TTS-Realtime 面向实时流式交互。 这些模型共同覆盖稳定生成、灵活设计、复杂对话、情境补全和实时交互,构成面向创作流程与产品系统的声音生产工具链。
开源与生态
MOSS-TTS 的技术路线强调可扩展、可复现和可部署。团队也在国产 GPU 生态中推进推理支持,使模型能够进入更多真实场景。 对研究社区而言,MOSS-TTS 的双架构和统一音频 tokenizer 提供了可比较、可消融的基线;对工程团队而言,它提供了从高质量离线合成到实时系统集成的落地路径。